机器学习 |
您所在的位置:网站首页 › python 决策树代码 › 机器学习 |
机器学习
|
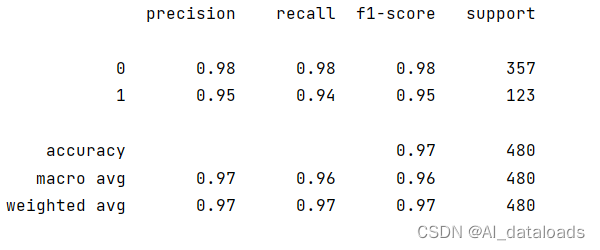
决策树是一种机器学习算法,常用于分类和回归问题。它是一种基于树结构的分析方法,通过一系列的决策规则将数据集划分成不同的类别或预测目标变量的取值。可通过我的另一篇博客:决策树回归纯享版,进一步了解决策树的定义。 在这里,我们学习的是用python代码实现关于分类的问题。 首先,这里有个数据表 '电信客户流失数据.xlsx'(可自行免费下载) 一、编写代码 1、导入库。 import pandas as pd from sklearn.model_selection import train_test_split from sklearn import tree from sklearn import metricspandas:用于数据处理和数据分析的库。它提供了灵活的数据结构和数据处理工具,使您能够加载、操作、分析和处理数据。 sklearn.model_selection:scikit-learn库中的模块,提供了用于数据集拆分、交叉验证和参数调优等功能的工具。train_test_split函数用于将数据集划分为训练集和测试集。 sklearn.tree:scikit-learn库中的模块,提供了决策树相关的功能和工具。DecisionTreeClassifier类是一个用于分类问题的决策树模型。 sklearn.metrics:scikit-learn库中的模块,提供了性能指标的计算和评估工具。classification_report函数用于生成分类问题的分类报告,包括准确率、召回率、F1值等指标。 2、读入数据读取Excel数据: 使用pd.read_excel函数读取名为"电信客户流失数据.xlsx"的Excel文件,并将数据保存在名为data的DataFrame中。 # 读取Excel文件数据 data = pd.read_excel('电信客户流失数据.xlsx') 3、提取特征矩阵和目标变量使用iloc方法从data中提取特征矩阵x和目标变量y。 x包含了所有列除了最后一列的数据,作为特征矩阵。y包含了最后一列的数据,作为目标变量。 x = data.iloc[:, :-1] # 特征矩阵,包含所有列除了最后一列 y = data.iloc[:, -1] # 目标变量,最后一列的数据 4、将数据集拆分为训练集和测试集调用train_test_split(x, y, test_size=0.2, random_state=42)函数将x和y划分为训练集和测试集,并将划分后的数据保存在data_train、data_test、target_train和target_test中。 test_size=0.2表示将20%的数据作为测试集。random_state=1用于设置随机种子,以确保每次划分的结果相同。 data_train, data_test, target_train, target_test = \ train_test_split(x, y, test_size=0.2, random_state=1) 5、创建决策树分类器对象使用tree.DecisionTreeClassifier(criterion='gini', max_depth=10, random_state=1)创建决策树分类器对象dtr。 criterion='gini'表示使用基尼系数来评估划分的质量。max_depth=10表示限制树的最大深度为10。random_state=1用于设置随机种子,以确保每次运行结果相同。 dtr = tree.DecisionTreeClassifier(criterion='gini', max_depth=10, random_state=1) 6、在训练集上拟合决策树模型使用dtr.fit(data_train, target_train)在训练集上拟合决策树模型,训练过程将特征矩阵data_train和目标变量target_train传入模型进行训练。 dtr.fit(data_train, target_train) 7、在训练集上进行预测使用dtr.predict(data_train)对训练集进行预测,将预测结果保存在train_predict中。 train_predict = dtr.predict(data_train) 8、打印训练集上的分类报告使用metrics.classification_report(target_train, train_predict)计算并打印训练集上的分类报告,其中target_train是实际的目标变量值,train_predict是模型在训练集上的预测结果。 print(metrics.classification_report(target_train, train_predict)) 9、代码整体 import pandas as pd from sklearn.model_selection import train_test_split from sklearn import tree from sklearn import metrics # 读取Excel文件数据 data = pd.read_excel('电信客户流失数据.xlsx') # 提取特征矩阵和目标变量 x = data.iloc[:, :-1] # 特征矩阵,包含所有列除了最后一列 y = data.iloc[:, -1] # 目标变量,最后一列的数据 # 将数据集拆分为训练集和测试集 data_train, data_test, target_train, target_test = train_test_split(x, y, test_size=0.2, random_state=42) # 创建决策树分类器对象 dtr = tree.DecisionTreeClassifier(criterion='gini', max_depth=10, random_state=1) # 在训练集上拟合决策树模型 dtr.fit(data_train, target_train) # 在训练集上进行预测 train_predict = dtr.predict(data_train) # 输出训练集上的分类报告 print(metrics.classification_report(target_train, train_predict)) 二、代码运行效果:
这段代码展示了如何使用决策树模型对电信客户流失数据进行分类预测,并通过分类报告评估模型在训练集上的性能。 |
【本文地址】